
Machine Learning and Artificial Intelligence
Machine learning is an important part of any up-to-date analytics practice. In short, it's the part of data analytics that knows how to identify patterns in the context of posed problems. It's different from other analytics functions such as data transformation and summarization in that it uses models to "understand" the data, and categorize, cluster, infer and predict outcomes. Another critical difference from other analytics functions is that ML/AI is not clear and exact, but is an imprecise science with outputs that are probable within a confidence level.
Artificial Intelligence is more generalized and seen by most academics and practitioners to be a superset (including ML) and at the same time, ML is essentially the leading edge of AI today. Other applications of AI are seen as either application/usage-specific - self-driving cars or stock trading - or generalized - think Hal from Space Odyssey.
There are many technologies and frameworks that are used to produce ML/AI models. At the lowest level are the programming languages such as Apache Spark, PyTorch and Tensor Flow. Data scientists use these to look for and test their observations. Within these frameworks are predefined algorithms that target different domains of problems. To drop a couple of names, "random cut forest" can be used to identify outliers and anomalies, and "naive bayes" can be used for classification problems.
One of the most important elements of a good machine learning practice is the identification or development of solid training and validation data sets. The training data set represents the range of data such that patterns of a given type are represented enough whereby a model can be derived. Once a model has been trained, the validation data set is offered and the "effectiveness" of the model is tested. The art of ML/AI is to not overtrain a model to the point where it is so specific that it cannot recognize patterns that are slightly different, but rather to train a model enough so that it is broadly useful. The fact is that the training set will never contain all of the possibilities that a model will be subjected to.
Once you have a model that is trained and has been proven effective, then it is time to deploy to places where data can be exposed to it, and it can do its thing. For instance, you might deploy it into a stream of data to classify data "on the way in." Another application might be to analyze stored data for anomalies, or to make predictions.
Within AWS, the premier service is Sagemaker, which offers a framework to develop, test and deploy models within an AWS Cloud context. But, ML/AI can happen outside of that. Indeed, it can happen anywhere you have some compute ability and a set of machine learning libraries.
Next, we'll consider how models are produced and the algorithms that might be employed.
Machine Learning Models
Below is a diagram that explains the process for model development.
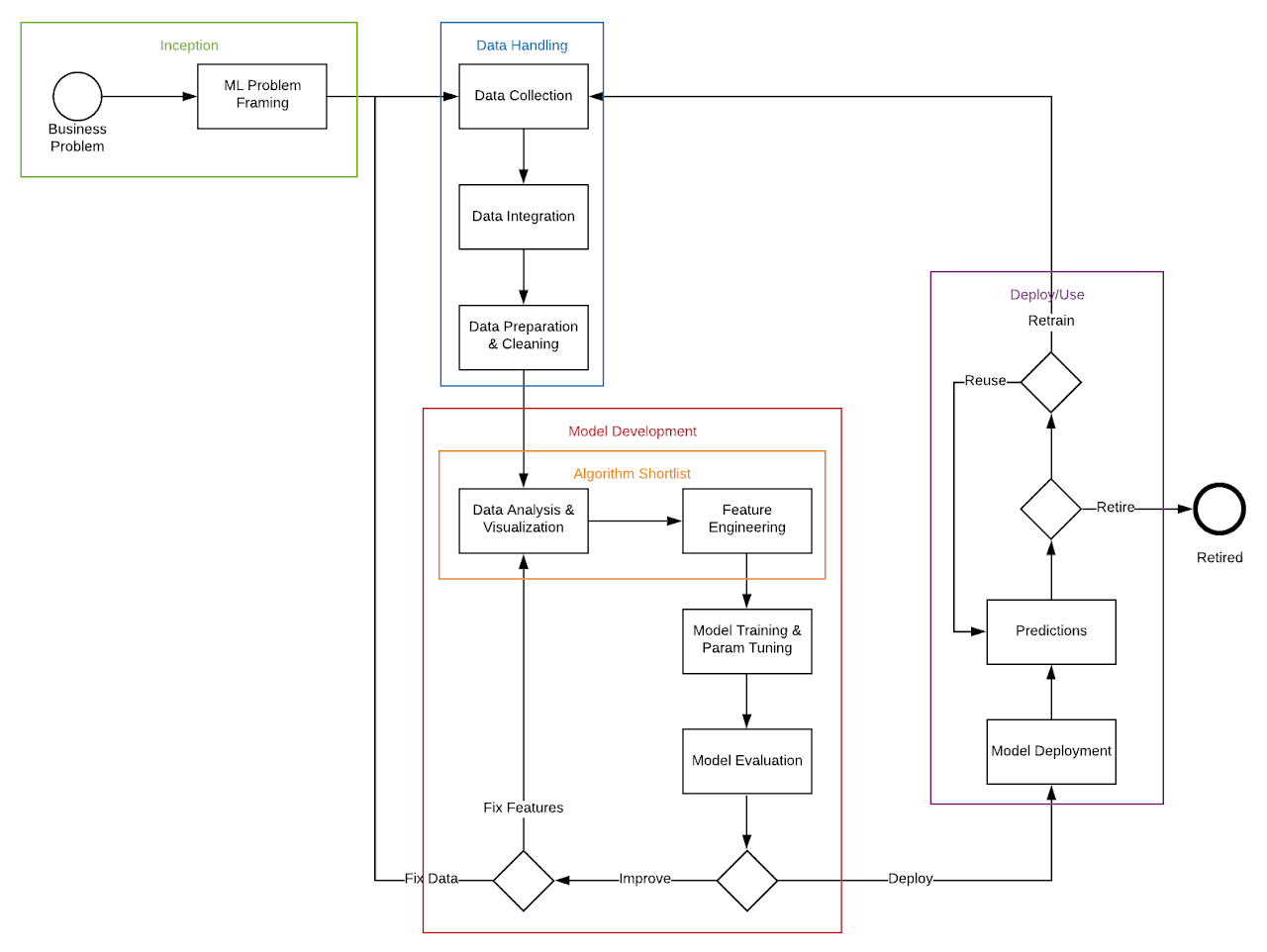
There are multiple Machine Learning stages:
- Inception – where the business problem is framed
- Data Handling – where collection, integration and cleanup occurs
- Model Development – an iterative phase that modifies the algorithm and tests the results over and over again until the desired outcome is achieved
- Deploy/Use – where the model is deployed for use
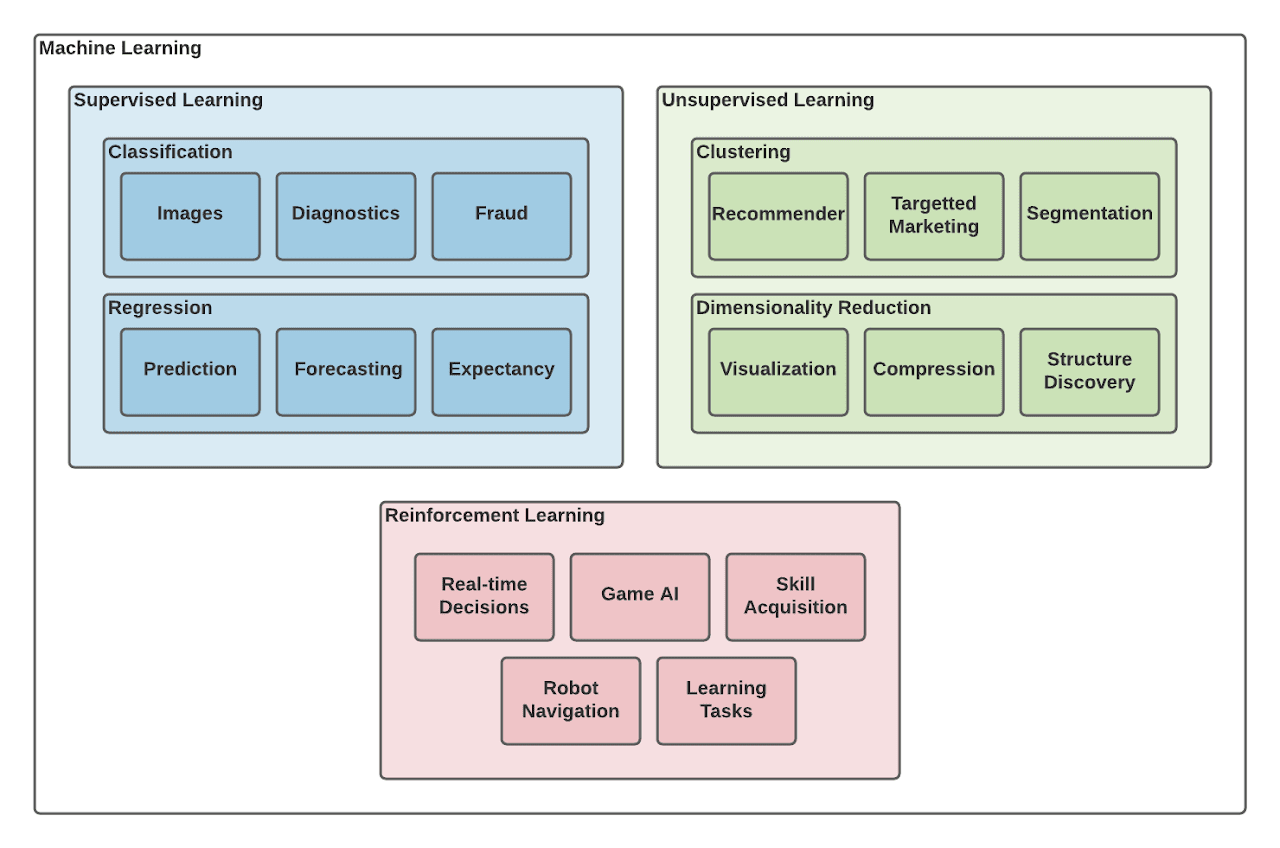
There are three learning styles that have to do with how models are trained, along with expectations for how they will operate.
- Supervised Learning – [classification and regression problems] a model is prepared through training. Then it is required to make predictions being corrected when those predictions are off.
- Unsupervised Learning – [clustering, dimensionality reduction, association rules] a model is created by identifying/deducing patterns that are present in the input data.
- Semi-supervised Learning – [classification and regression] input data is a mixture of labeled and unlabeled data. The model has to "learn" patterns for organizational and predictive purposes.
Next, algorithms need discussion. Here is a list of them with a short description grouped by the problem type that they might be applied to.
| Algorithm Type | Application | Example Algorithms |
|---|---|---|
| Regression | Relationships between variables that are iteratively refined by observing error in the predictions made | Ordinary Least Squares Regression Linear Regression Logistic Regression |
| Instance-based | Winner-take-all and memory-based decisions when you have instances/examples of training data | Locally Weighted Learning Self-Organizing Map k-Nearest Neighbors |
| Decision Tree | Need decisions based on actual values of attributes in the data; regression and classification | Classification and Regression Tree Decision Stump Conditional Decision Trees |
| Bayesian | Use prior knowledge of conditions to predict the probability of an event | Naïve Bayes Multinomial Naïve Bayes Gaussian Naïve Bayes |
| Clustering | Use inherent patterns in the data to best organize the data into groups with the maximum things in common | k-Means k-Medians Hierarchical Clustering |
| Association Rule Learning | Using rules to discover associations that are important or commercially useful | Apriori Eclat |
| Artificial Neural Network | Pattern matching that is commonly used in regression and classification problems | Perceptron Back Propagation Hopfield Network |
| Deep Learning | Extending artificial neural networks; scaling out network and data set size as well as complexity | Convolutional Neural Network Stacked Auto-Encoders Deep Belief Network |
| Dimensionality Reduction | When you need to visualize dimensional data or to simplify data which can then be used in a supervised learning method | Principal Component Analysis Partial Least Squares Regression Projection Pursuit |
| Ensemble | Composition of multiple weaker models that are independently trained and whose predictions are combined in some way to make the overall prediction | AdaBoost Weighted Average Random Forest Stacked Generalization |
The next question is how to select the appropriate algorithm for the task at hand. Below is a flowchart from "scikit-learn" that is helpful.
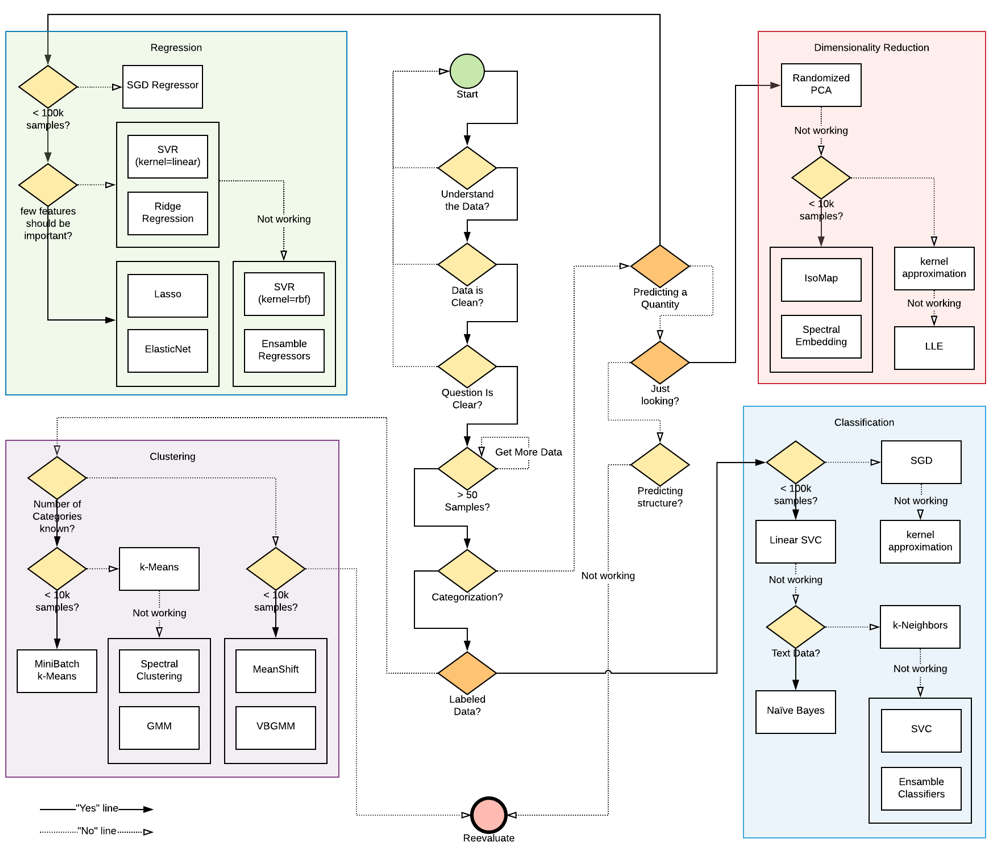
In the end, machine learning is about solving business problems through pattern recognition and statistical analysis. It's a technique that can be used across the breath of the data that is available today: textual to streaming video. It is not perfect and generally requires a lot of data to train, tweak, test, and deploy. If data changes its complexion, then a model will become obsolete and will either need to be retrained or abandoned. Therefore, machine learning, as it is practiced today, requires a continued commitment of time and resources.
Final Thought
Machine learning and artificial intelligence is a broad and complicated subject. At GSA, we are interested in using it to enhance what we do as much as we can. ML/AI offers tremendous potential in helping us to handle our data both wisely and with speed. In that it is a "frontier" set of technologies, we will have to be cautious, but aggressively hopeful as we bring it into our systems and services.